
Image Colorization using GANs
Project Overview
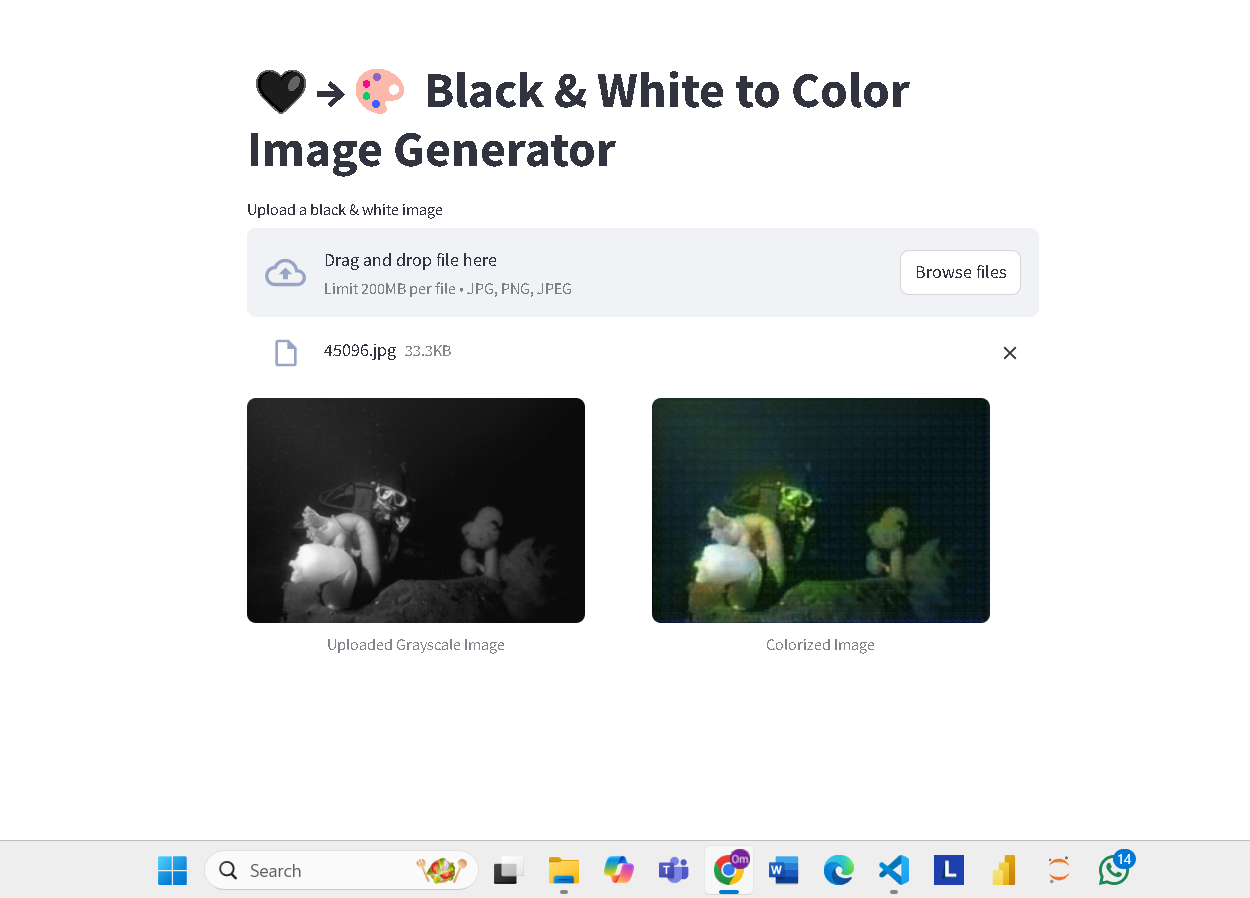
This Image Colorization using GANs project demonstrates the power of deep learning and Generative Adversarial Networks (GANs) for transforming grayscale images into realistic colorized versions. Leveraging the Pix2Pix architecture, the model utilizes a Conditional GAN to learn the mapping between grayscale images and their color counterparts, producing high-quality and visually appealing results. Built with PyTorch, this project focuses on a U-Net inspired generator and a PatchGAN discriminator for effective image generation. It supports a full training pipeline, including optimization strategies, loss functions, and model evaluation metrics like SSIM and PSNR for assessing image quality.
Key Insights
- Conditional GANs (cGANs) enable realistic colorization by learning conditional relationships between grayscale and color images.
- Pix2Pix architecture utilizes a U-Net inspired Generator and PatchGAN Discriminator for high-quality, detail-preserving image colorization.
- Combining L1 Loss and GAN Loss ensures pixel-accurate results while maintaining visual appeal by balancing reconstruction and adversarial objectives.
- PatchGAN Discriminator enhances image quality by focusing on local image patches rather than entire images, capturing fine details.
- Gradient clipping and learning rate scheduling stabilize training and prevent issues like exploding gradients, ensuring smooth model convergence.
Technical Implementation
- Model Architecture:
- Implemented a Conditional Generative Adversarial Network (cGAN) based on the Pix2Pix architecture.
- The Generator follows a U-Net-inspired encoder-decoder structure to convert grayscale input to colorized images.
- The Discriminator uses a PatchGAN approach to classify real/fake image patches for improved detail preservation.
- Loss Functions:
- Used a combination of Adversarial Loss (BCE) and Reconstruction Loss (L1) for stable training and high-quality output generation.
- Training Process:
- Trained the model with the Adam optimizer (learning rate 0.0002) and gradient clipping for stable convergence.
- Implemented StepLR learning rate scheduler to adjust the learning rate during training for optimal performance.
- Image Input and Output:
- Input grayscale images are resized to 128x128 resolution for consistent processing and output.
- Generated images are output as 3-channel RGB color images from the model.
- Evaluation Metrics:
- SSIM (Structural Similarity Index): Measures the perceived quality of the generated colorized images by comparing structural similarity to the ground truth.
- PSNR (Peak Signal-to-Noise Ratio): Measures how close the generated image is to the ground truth in terms of pixel-wise similarity.
Image Preview
Key Learnings
- Conditional GANs (cGANs) are effective for generating realistic colorized images by learning the mapping between grayscale and color images.
- U-Net architecture in the generator ensures high-quality output by using skip connections to preserve important features in the image.
- PatchGAN discriminator focuses on local image patches, which helps in generating high-frequency details and fine textures.
- Adversarial loss combined with reconstruction loss (L1) provides a balanced approach to training, maintaining both visual fidelity and content accuracy.
- Training stability can be enhanced using techniques like gradient clipping and learning rate scheduling.